如何基于Python批量下载音乐
(编辑:jimmy 日期: 2024/11/20 浏览:3 次 )
这篇文章主要介绍了如何基于Python批量下载音乐,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
音乐是生活的调剂品,目前很多的音乐只能播放不能下载。生为技术员的我们,怎么甘心呢?
知识点:
- requests
- 正则表达式
开发环境:
- 版 本:anaconda5.2.0(python3.6.5)
- 编辑器:pycharm
第三方库:
- requests
- parsel
网页分析
目标站点:http://music.taihe.com/search"_blank" href="http://music.taihe.com/song/243093242" rel="external nofollow" >走马为例

打开开发者工具,选择network -> media -> 刷新网页就能获取到音乐的真实地址
但是得到的地址在查看源码中是读取不到的,肯定是百度音乐对其进行了隐藏。这种时候一般会有两种情况。第一种是使用了 JavaScript 对请求连接进行了拼接或加密,第二种是数据被隐藏了。由于我们不清楚是出现了那种情况。所以我们只能慢慢的去分析请求的数据。

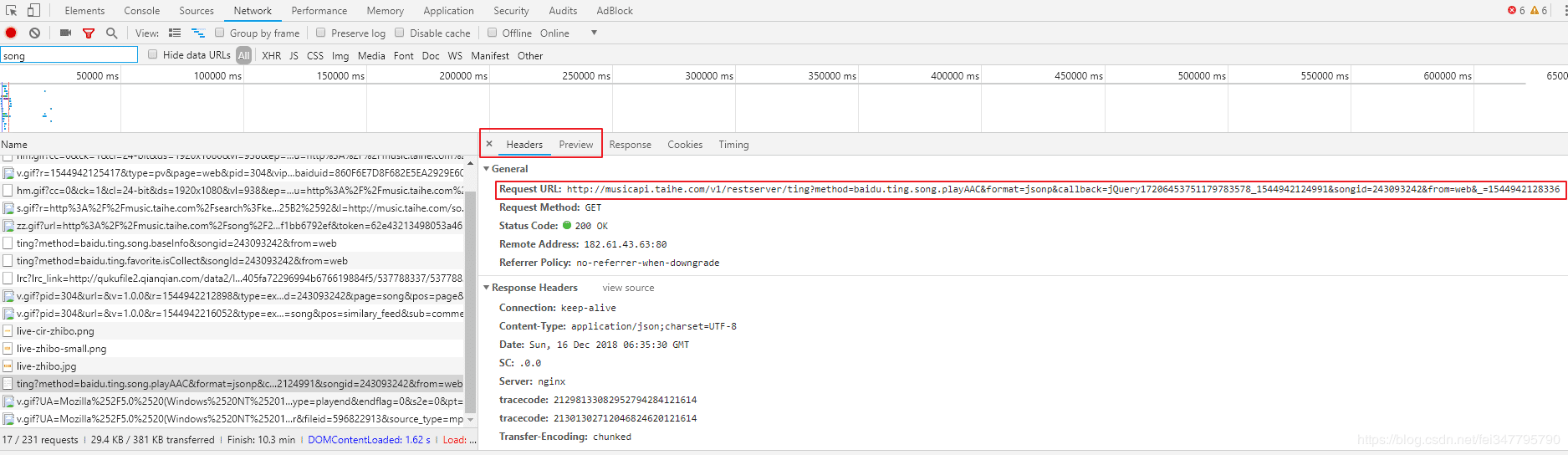
经过分析我们可以看到真实的音乐地址是存在于这个API里面http://musicapi.taihe.com/v1/restserver/ting"text-align: left">前面我们得到了音乐的真实地址,接下来我们就是分析真实地址的 url ,以期待得到下载所有音乐的诀窍。


仔细分析一下 url 就可以发现,"text-align: center">
使用开发者工具,查看网页源码就能查看到songid的位置,如果我们分析一个歌手页面的url你会发现同样可以构造。
到此,整个网页分析就结束了。
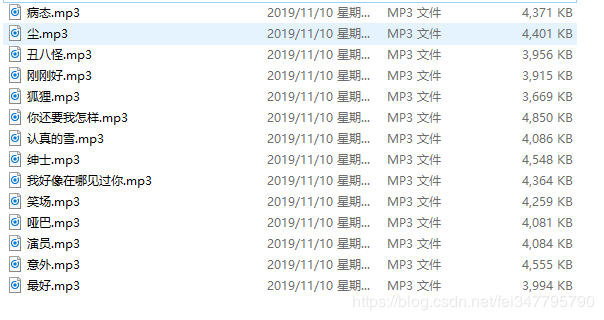
实现效果

完整代码
import re
import requests
"""获取音乐的songid"""
url = 'http://music.taihe.com/artist/2517'
response = requests.get(url=url)
html = response.text
sids = re.findall(r'href="/song/(\d+)" rel="external nofollow" ', html)
return sids
"""获取下载链接"""
api_url = f'http://musicapi.taihe.com/v1/restserver/ting"""下载音乐"""
response = requests.get(music_url)
content = response.content
save_file(music_name+'.mp3', content)
"""保存音乐"""
with open(file=filename, mode="wb") as f:
f.write(content)
if __name__ == "__main__":
for song_id in get_songid():
music_name, music_url = get_music_url(song_id)
download_music(music_name, music_url)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
下一篇:Python实现报警信息实时发送至邮箱功能(实例代码)